
K-Means Clustering
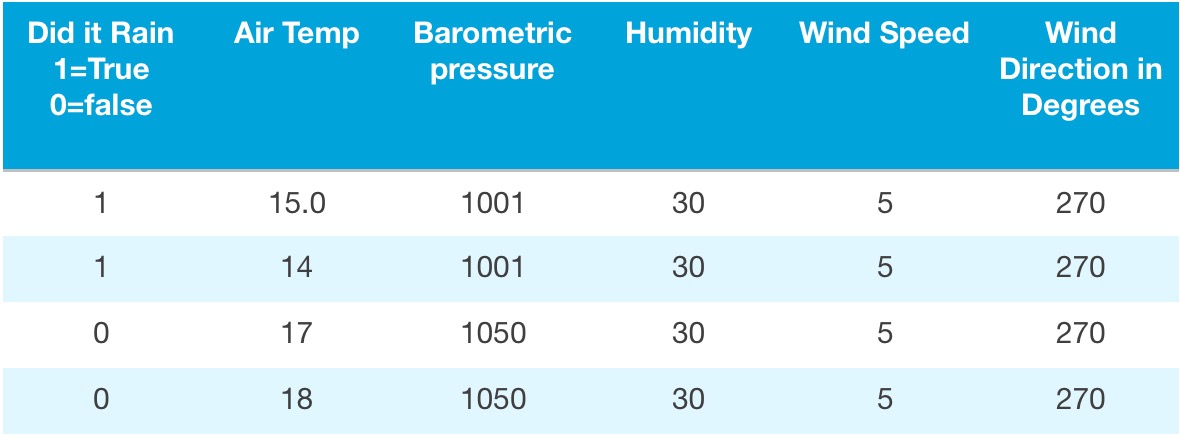
How do you look at Customer segmentation? Say you have a lot of customers who are high spending customers and a lot of customers who are low spending customers buying your products. Now you want to offer a loyalty discount only to the low spending customers to get them to buy more of your product. What is the centre point of the high spenders and the centre point of the low spenders. If you took a straight average or mean you would be ignoring both customer bases.
Let us look at it using a very simple data set like this.
0.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
The first thing you can see is we seem to have two distinct types of customers below 1.0 and around 9.0. This can be shown visually as above.
 However what if you had a million customers, you could never hope to do this simply. This is where k-Means clustering comes to the rescue. The value of K however is what you need to tweak as you may have k=2 or even k=3. Usually however K is reasonably low but in the most degenerate case of course k= total rows.
However what if you had a million customers, you could never hope to do this simply. This is where k-Means clustering comes to the rescue. The value of K however is what you need to tweak as you may have k=2 or even k=3. Usually however K is reasonably low but in the most degenerate case of course k= total rows. This is an Unsupervised learning algorithm as we are in the dark about how many clusters or where exactly that centre is. The machine will learn this by looking at the data, and the human operator will interpret the results.
Cost of Compute
The standard KMeans algorithm aims at minimizing the sum of squares of the distance between the points of each set: the squared Euclidean distance. Once you have computed the model by doing a train on the dataset
val result = KMeans.train(< inData >>>, < clusterNumber >, < Iterations >)
you can evaluate the result by using Within Set Sum of Squared Errors (WSSE) This is the sum of the distances of each observation in each K cluster. The idea is to find the optimum K between K=1 and K=Size of Set that gives you the most detail with the minimum distance of the points to the centre of the cluster. The centre of the cluster is called the Centroid, and back K has an associated centroid.
One way is generally to either know some Domain specific knowledge or to empirically retrain the model with different K and capture the output every time of the Sum Squared difference ie the Computed Cost.
You also need to bear in Mind that there are Outliers that might push your cluster centres beyond what the should be.
Outliers
The problem with Outliers is they push the Centroids to a slightly different place than they would be without these pesky outliers.
Given an unsupervised algorithm you can not just see an outlier and report it as an error and continue, it is down to us to prepare the data. The two main options are to try and remove your outliers before the start of the process which may require domain specific knowledge. The other solution is to run your K means with Different K values looking at when the Sum Squared increases dramatically to find an outlier. You should always aim form small Sum Squares.
Let me show you what I mean here is some code for a K-Means algorithm using the above data set
val data = sc.textFile("data/artifacts/kmeans_data.txt")
//Data looks like
/*
* 0.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
*/
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// Cluster the data into two classes using KMeans
val numClusters = 2
val numIterations = 20
val clusters = KMeans.train(parsedData, numClusters, numIterations)
// Evaluate clustering by computing Within Set Sum of Squared Errors
val WSSSE = clusters.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + WSSSE)
clusters.toPMML(System.out)
Now with the data set I used before at K=2 the results are
Within Set Sum of Squared Errors = 0.11999999999994547
This is less than 1
Now if I add an outlier, by adding another row to the input file such as
100 100 100
Now my Distance is
Within Set Sum of Squared Errors = 364.62
Now to show that Increasing K may assist, If I make my K=3 then I get
Within Set Sum of Squared Errors = 0.11999999999994547
This goes to show that plotting your Sum Squared against your K can itself show up outliers.
However there are some other tricks in the toolbox that may help.
Here is some helper code
//This tells you which centroid and how many items
val predict = clusters.predict(parsedData)
println(predict.countByValue)
//output is Map(0 -> 3, 1 -> 1, 2 -> 3)
//3 items Centroid 0 1 in Centroid 1 and 3 in Centroid 2
//this tells you the value of the Centroids
val centres = clusters.clusterCenters
println(centres.toSeq)
//output is like WrappedArray([0.1,0.1,0.1], [100.0,100.0,100.0], [9.1,9.1,9.1])
//This gives information about your Centroids you can save for later
clusters.toPMML(System.out)
//This shows you the data points and to which centroid it relates to
val centroidAndData = parsedData.map{ point =>
val prediction = clusters.predict(point)
(point.toString, prediction)
}
centroidAndData.collect().foreach(println)
//The output looks like
/*
* ([0.0,0.0,0.0],0)
([0.1,0.1,0.1],0)
([0.2,0.2,0.2],0)
([9.0,9.0,9.0],2)
([9.1,9.1,9.1],2)
([9.2,9.2,9.2],2)
([100.0,100.0,100.0],1)
*/
As always be careful if using multiple partitions and machines as stdout/println is on that host not the driver of the spark/ML.
People who enjoyed this article also enjoyed the following:
Naive Bayes classification AI algorithm
K-Means Clustering AI algorithm
Equity Derivatives tutorial
Fixed Income tutorial
And the following Trails:
C++Java
python
Scala
Investment Banking tutorials
HOME
